
Blog post
Clash of the cultures
“If the goal as a field is to use data to solve problems, then we need to move away from the exclusive dependence on data models and adopt a more diverse set of tools” – Leo Breiman

The epistemic trade-off
Predictive accuracy versus traditional statisical model methodology
“Statistical Modeling: The Two Cultures”
There is a subtle yet fundamental distinction between the core objective of conventional statistical modelling versus data science. Historically conventional statistical modelling focused on uncovering the internal structure of the system being modelled. In other words, its focus is to explain the data, which then structure predictions. Whereas machine learning tends to focus on the predictive accuracy of the model – using the data to make predictions. This key difference was outlined by the distinguished statistician, Leo Breiman, in his paper “Statistical Modeling: The Two Cultures”. Despite being published in 2001 during the early days of applied machine learning, Breiman’s paper remains remarkably relevant today as the role of structure and theory in modelling continues to be debated. Breiman argued that always assuming data is generated by some kind of specific stochastic model has led to ‘questionable conclusions about the underlying mechanism’ and an unwillingness to try other techniques with potential to be more effective. At the time, he circulated his paper among other leading statisticians, publishing their comments, both supporting and contradicting his work. For Breiman, how well a model emulates nature can be judged by how accurate its predictions are.
Nature's black box
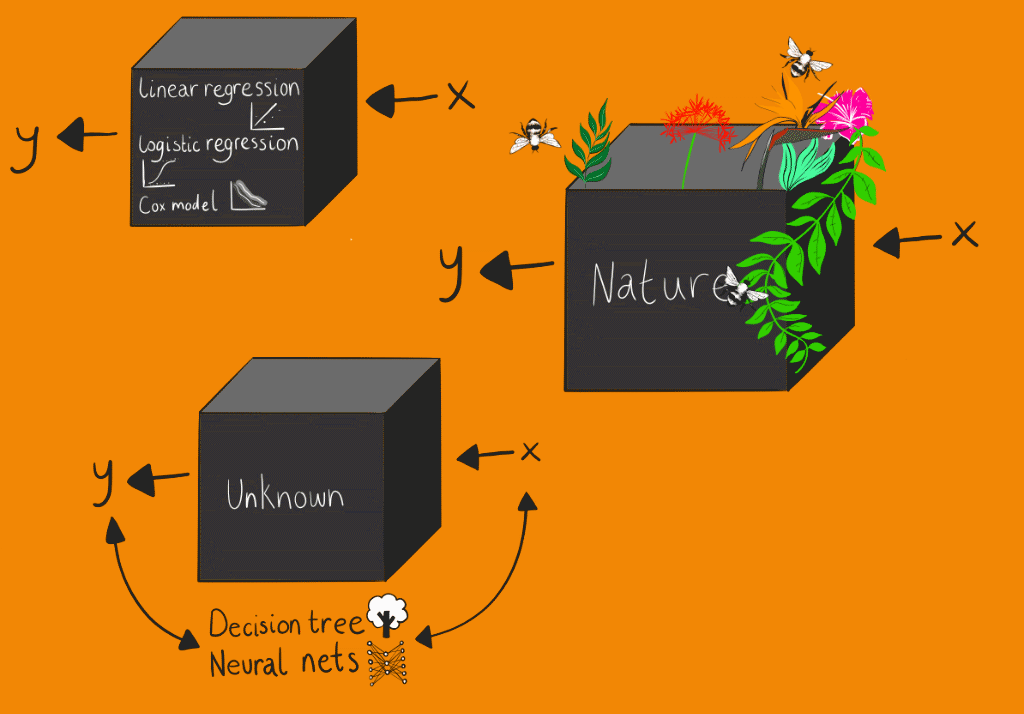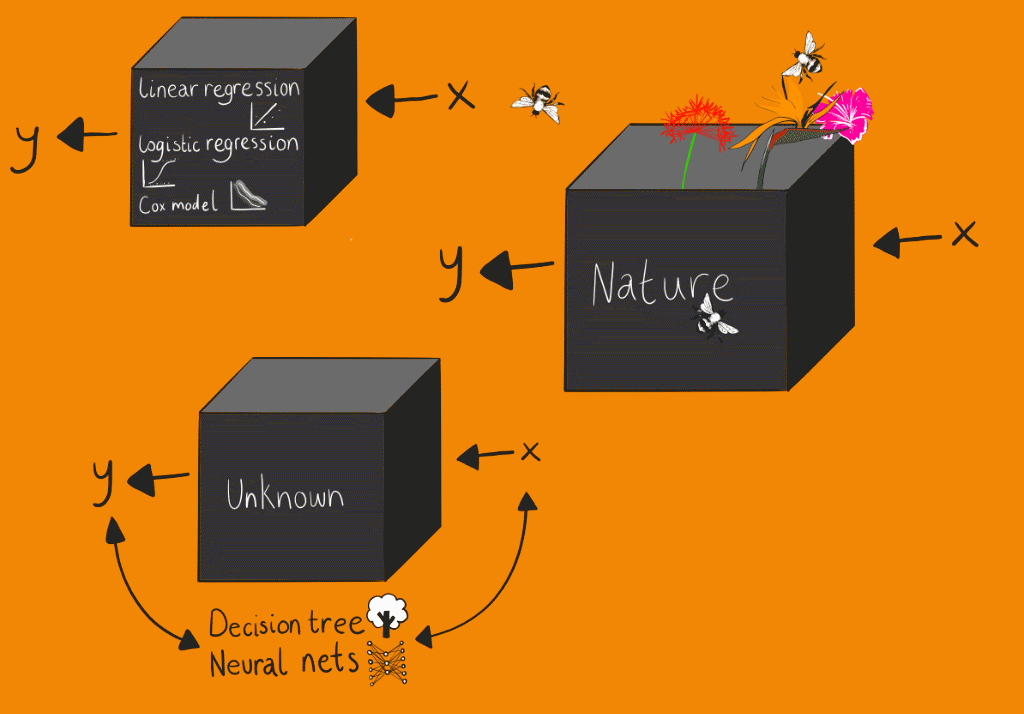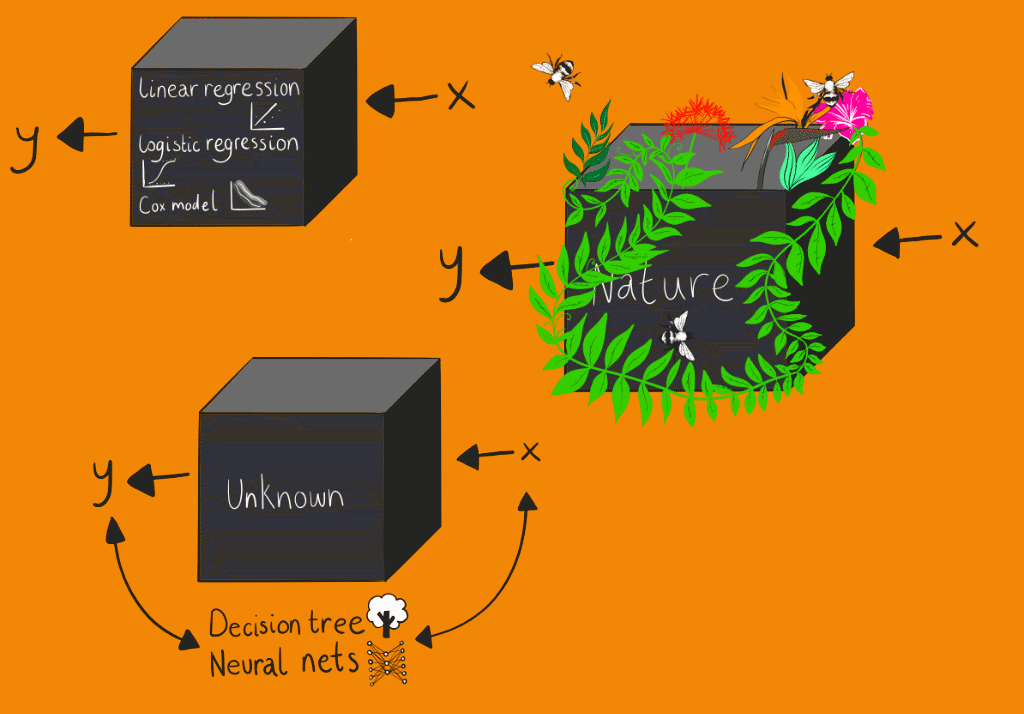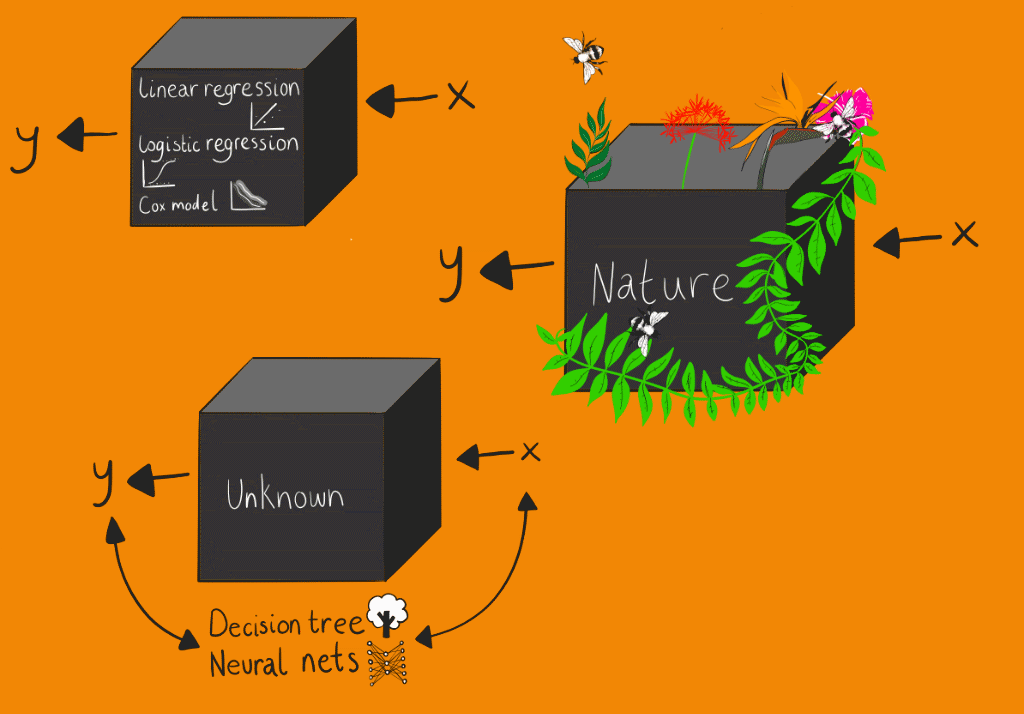
The conventional statistical culture, which Breiman refers to as the “data modelling” culture, assumes the box contains some form of stochastic data model. The parameters for this stochastic data model can be estimated from the input data. The effectiveness of the model is then based on the goodness-of- fit tests and residuals analysis. Machine learning modelling, which Breiman refers to as the algorithmic modelling culture, treats the contents of the box as unknown, or at least partly unknowable. Machine learning algorithms are generally based on optimising performance against metrics – the most critical being accuracy. This approach centres on finding a function that operates on the input variable to find the response variable. However, this black box approach to modelling has a fundamental explainability problem, while conventional statistical models produce representations of relationships between variables that can easily be understood. Indeed, it still remains unclear how deep learning models are so effective. Although as Tukey stated “far better an approximate answer to the right question, which is often vague, than the exact answer to the wrong question, which can always be made precise.”
New perspectives: Shifts from design to outcome

Rashomon and the multiplicity of data models
The Rashomon Effect is based on the Japanese movie that depicts different characters recounting the same event from contrasting perspectives. Breiman highlights an issue in both conventional statistical modelling and machine learning, where multiple models represent the same accuracy but different representations of the variable’s relationship. He argues this is an issue that needs attention, citing remedial approaches such as the aggregation of competing sets of models. The multiplicity problem is evident in contemporary machine learning model experimentation and versioning practices. For instance, the minuscule differences in accuracy in Kaggle competitions. Variability at the top of the leader board becomes a game of decimal points – seemingly governed by luck.
Occam's Razor - simplicity versus accuracy
The second lesson, Occam’s Razor – simplicity versus accuracy, outlines the tension created by increased accuracy in predictive models coinciding with decreased interpretability. For Breiman not being able to understand the mechanism that produce a prediction is problematic. However, he views favouring simple yet interpretable functions as potentially sacrificing accuracy. Breiman states ‘using complex predictors may be unpleasant, but the soundest path is to go for predictive accuracy first, then try to understand why.
Bellman and the curse of dimensionality
Breiman’s third and final lesson references Richard Bellman’s famous phrase “the curse of dimensionality”. Bellman and the curse of dimensionality refers to the traditional approach of reducing the number of prediction variables for a model by calculating the most “significant” features. These features are then used to reduce dimensionality by using them to form a smaller set of prediction variables. Breiman, however, highlights that dimensionality can be a blessing – higher dimensionality can mean more information for prediction. Breiman endorses the approach of adding functions of predictor variables rather than removing them. He states “there may be thousands of features. Each potentially contains a small amount of information.”
At the time of writing, Breiman referred to the “small community” known as machine learning he was inducted into while working as a consultant. Since then, there has been an explosion in machine learning research and applications and popular neural network architectures now include Transformers, Convolutional Neural Networks and Recurrent Neural Nets. However, Breiman’s lessons endure to this day, and predicts the continued tensions in contemporary modelling.
Breiman concludes by emphasizing the importance of approaching modelling from the data and the problem at hand, rather than a commitment to a particular modelling paradigm. There are many modelling paradigms and cultures that currently coexist, clash and at times are even complementary.
A necessary good or a necessary evil?
While machine learning is increasingly being used in a range of contexts, sometimes alongside more conventional statistical modelling, cultural and epistemic tensions still exist. “State-of-the-world” models, with mathematically defined theoretical boundaries and methods, are often used in financial modelling. Machine learning models represent a radical departure from these models which are built around a structural concept which represents a simplified view of the world. The statistical relationships in neural networks are not driven by theory or causation, instead they are based on empiricism and a balance between accuracy and generalization.
Even within the field of machine learning the role of theory and structure is contested and differing perspectives were illustrated in a discussion between Yann LeCun and Christopher Manning on the role of deep learning and innate priors. Computer vision and large language models, which have been immensely successful applications of neural networks may seem like they are beyond the empiricist versus data model approach. However, the role of structure and innate priors in neural networks has some overlaps with the epistemic tension Breiman outlined.
LeCunn argued that structure to a limited degree may be a necessary evil. However, LeCunn notes deep learning is capable of learning from masses of data to create complex representations and patterns without innate priors that introduce a preliminary structure of the world. Christopher Manning disagreed in favour of domain-specific knowledge and structure as a necessary good that could support better generalizing and interpretable machines.At the time of writing, Breiman referred to the “small community” known as machine learning he was inducted into while working as a consultant. Since then, there has been an explosion in machine learning research and applications and popular neural network architectures now include Transformers, Convolutional Neural Networks and Recurrent Neural Nets. However, Breiman’s lessons endure to this day, and predicts the continued tensions in contemporary modelling.
Breiman concludes by emphasizing the importance of approaching modelling from the data and the problem at hand, rather than a commitment to a particular modelling paradigm. There are many modelling paradigms and cultures that currently coexist, clash and at times are even complementary.